Overview of the configuration process
Hadoop configuration can be incredibly complex. However, with DQ, the goal is simply to leverage Hadoop to allocate compute resources to execute Spark jobs. As a result, the only client-side configurations required are:
- Security protocol definition
- Yarn Resource Manager endpoints
- Storage service (HDFS or Cloud storage).
Once you've defined the Hadoop client configuration, point the DQ Agent at the folder that contains the client configuration files. The DQ Agent is then able to use the Hadoop client configuration to submit jobs to the specified Hadoop cluster.
Additional considerations
DQ jobs running on Hadoop are Spark jobs. DQ will use the storage platform defined in the fs.defaultFS setting to distribute all of the required Spark libraries and specified dependency packages like drivers files. This allows DQ to use a version of Spark that is different than the one provided by the cluster. If it is a requirement to use the Spark version provided by the target Hadoop cluster, obtain and use a copy of the yarn-site.xml and core-site.xml from the cluster.
In some cases, the required Hadoop client configuration requires the DQ Agent to run on a Hadoop Edge node within the cluster. This can happen for a number of reasons. Namely, native dependency packages are required, network isolation from the subnet that hosts the DQ server, complex security configuration, and so on. In these circumstances, you can deploy the DQ Agent on a cluster Edge Node that contains the required configurations and packages. In this setup, the DQ Agent uses the existing Hadoop configuration and packages to run DQ checks on the Hadoop cluster.
Before you begin
Before you can configure Hadoop, create the config folder. Execute the following commands:
cd $OWL_HOME
mkdir -p config/hadoop
echo "export HADOOP_CONF_DIR=$OWL_HOME/config/hadoop" >> config/owl-env.sh
bin/owlmanage.sh restart=owlagentMinimum configuration settings
The following is a minimal configuration with Kerberos and TLS disabled. It is typically only applicable in Cloud Hadoop scenarios (EMR/Dataproc/HDI). Cloud Hadoop clusters are ephemeral and do not store any data, because the data is stored and secured in Cloud Storage.
export RESOURCE_MANAGER=<yarn-resource-manager-host>
export NAME_NODE=<namenode>
echo "
<configuration>
<property>
<name>hadoop.security.authentication</name>
<value>simple</value>
</property>
<property>
<name>hadoop.rpc.protection</name>
<value>authentication</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://$NAME_NODE:8020</value>
</property>
</configuration>
" >> $OWL_HOME/config/hadoop/core-site.xml
echo "
<configuration>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>$RESOURCE_MANAGER:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>$RESOURCE_MANAGER:8032</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>$RESOURCE_MANAGER:8088</value>
</property>
</configuration>
" >> $OWL_HOME/config/hadoop/yarn-site.xmlConfigure cloud storage
When deploying a Cloud Service Hadoop cluster from any of the major Cloud platforms, it is possible to use Cloud Storage rather than HDFS for dependency package staging and distribution.
-
Create a new storage bucket.
-
Provide both the Hadoop cluster and the instance running the DQ Agent access to the bucket. In most cases, use a Role that is attached to the infrastructure. For example, AWS Instance Role with bucket access policies.
-
In core-site.xml, set
fs.defaultFSto the bucket path instead of HDFS.
Configure the DQ Agent for Hadoop
After creating the Hadoop client configuration, use the Agent Configuration console to configure the DQ Agent to use Hadoop.
- Sign in to your web instance of Collibra DQ.
- Hover your cursor over the
 icon and click Admin Console.
icon and click Admin Console.
The Admin Console opens. - Click Agent Configuration.The Agent Configuration page opens.
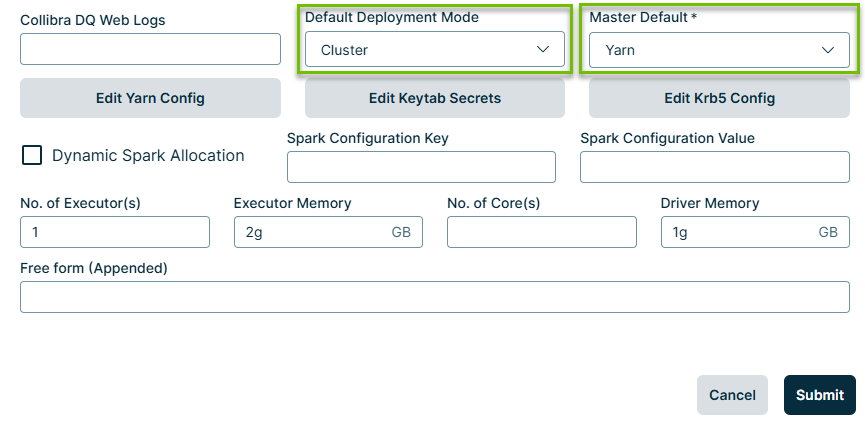
- In the list of DQ Agents, find the agent that you want to modify. Under Actions, click the Actions button and click Edit. The Edit Agent modal displays.
- Set the Master Default field to Yarn.
- Set the Default Deployment Mode to Cluster.
- Click Submit.
Secure configuration settings using Kerberos
Use Kerberos to secure Hadoop clusters that are deployed on-premises, because they are typically multi-tenant and not ephemeral. Additionally, enable TLS for all HTTP endpoints. HDFS may also be configured for a more secure communication with additional RPC encryption.
export RESOURCE_MANAGER=<yarn-resoruce-manager-host>
export NAME_NODE=<namenode>
export KERBEROS_DOMAIN=<kerberos-domain-on-cluster>
export HDFS_RPC_PROTECTION=<authentication || privacy || integrity>
echo "
<configuration>
<property>
<name>hadoop.security.authentication</name>
<value>kerberos</value>
</property>
<property>
<name>hadoop.rpc.protection</name>
<value>$HDFS_RPC_PROTECTION</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://$NAME_NODE:8020</value>
</property>
</configuration>
" >> $OWL_HOME/config/hadoop/core-site.xml
echo "
<configuration>
<property>
<name>hadoop.security.authentication</name>
<value>HDFS/_HOST@$KERBEROS_DOMAIN</value>
</property>
</configuration>
" >> $OWL_HOME/config/hadoop/hdfs-site.xml
echo "
<configuration>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>$RESOURCE_MANAGER:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>$RESOURCE_MANAGER:8032</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>$RESOURCE_MANAGER:8090</value>
</property>
</configuration>
" >> $OWL_HOME/config/hadoop/yarn-site.xmlConfigure DQ Agent for Kerberos
When the target Hadoop cluster is secured by Kerberos, DQ checks (Spark jobs) require a Kerberos credential. This typically means that the DQ Agent will need to be configured to include a Kerberos keytab with each DQ check.
- Sign in to your web instance of Collibra DQ.
- Hover your cursor over the icon and click Admin Console.
The Admin Console opens. - Click Agent Configuration.The Agent Configuration page opens.
- In the list of DQ Agents, find the agent that you want to modify. Under Actions, click the Actions button and click Edit. The Edit Agent modal displays.
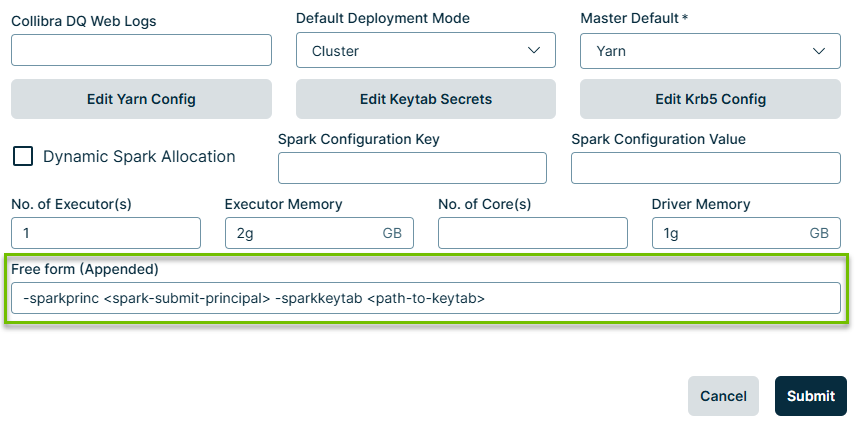
- In the Free form (Appended) field, enter the following command:
- Click Submit.
-sparkprinc <spark-submit-principal> -sparkkeytab <path-to-keytab>